下载 Ollama
前往 Ollama官网
下载客户端,下载完成后点击Install安装即可。
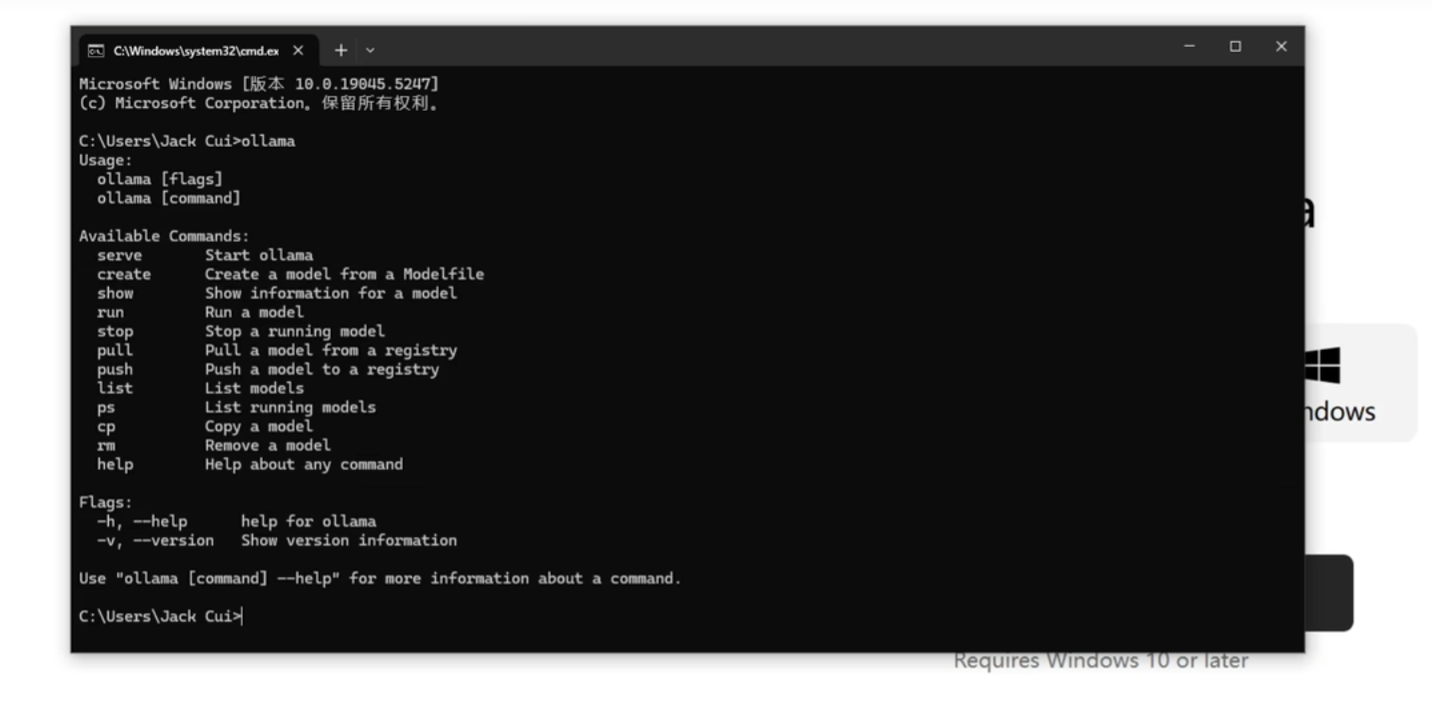
完成后会自动安装在C:盘的AppData文件夹下,命令行输入ollama后,显示下图中的信息表明安装成功。
下载模型
在官网界面点击 DeepSeek-R1
超链接
跳转到DeepSeek安装界面,选择对应大小的模型复制右边的安装代码,打开命令行粘贴即可自动安装了,这里附上所有模型的安装显存需求:
| 模型大小 | 显存需求 | 显卡推荐 |
|---|---|---|
| 1.5b | ≈1GB | GTX 1050 及以上 |
| 7b | ≈4GB | RTX 3060 及以上 |
| 8b | ≈4.5GB | RTX 3070 及以上 |
| 14b | ≈8GB | RTX 4070及以上 |
| 32b | ≈18GB | RTX 4080及以上 |
| 70b | ≈40GB | RTX 4090 或 A100 及以上 |
如果想查看显存可以按照如下步骤:任务管理器 > 性能 > GPU
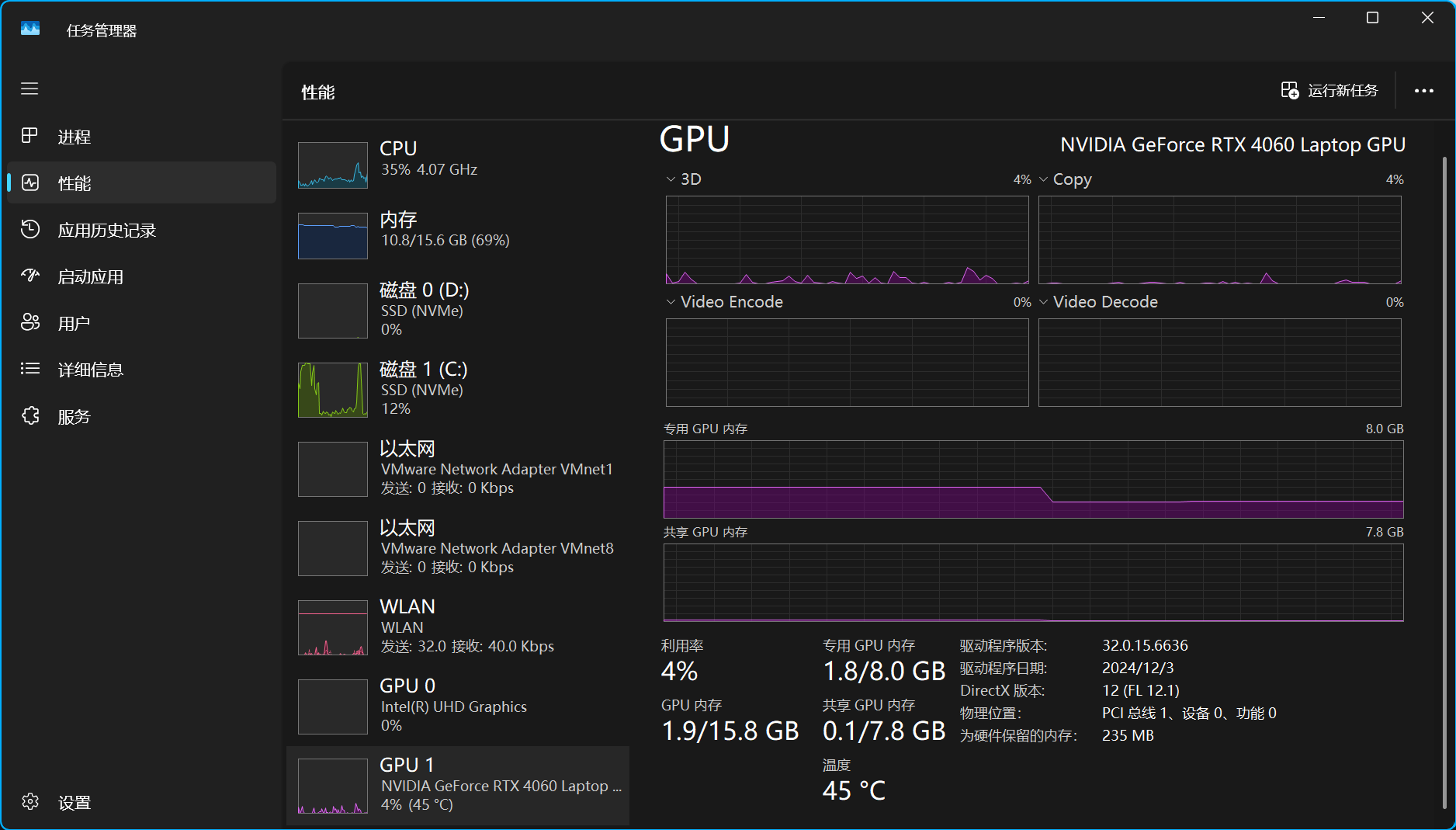
这里有两个参数,专用GPU内存 表示显卡自身的显存,共享GPU内存 表示显存不用的时候向内存条借的显存,以专用GPU内存为准即可,具体性能需实测得到。
使用方法
查询模型列表:
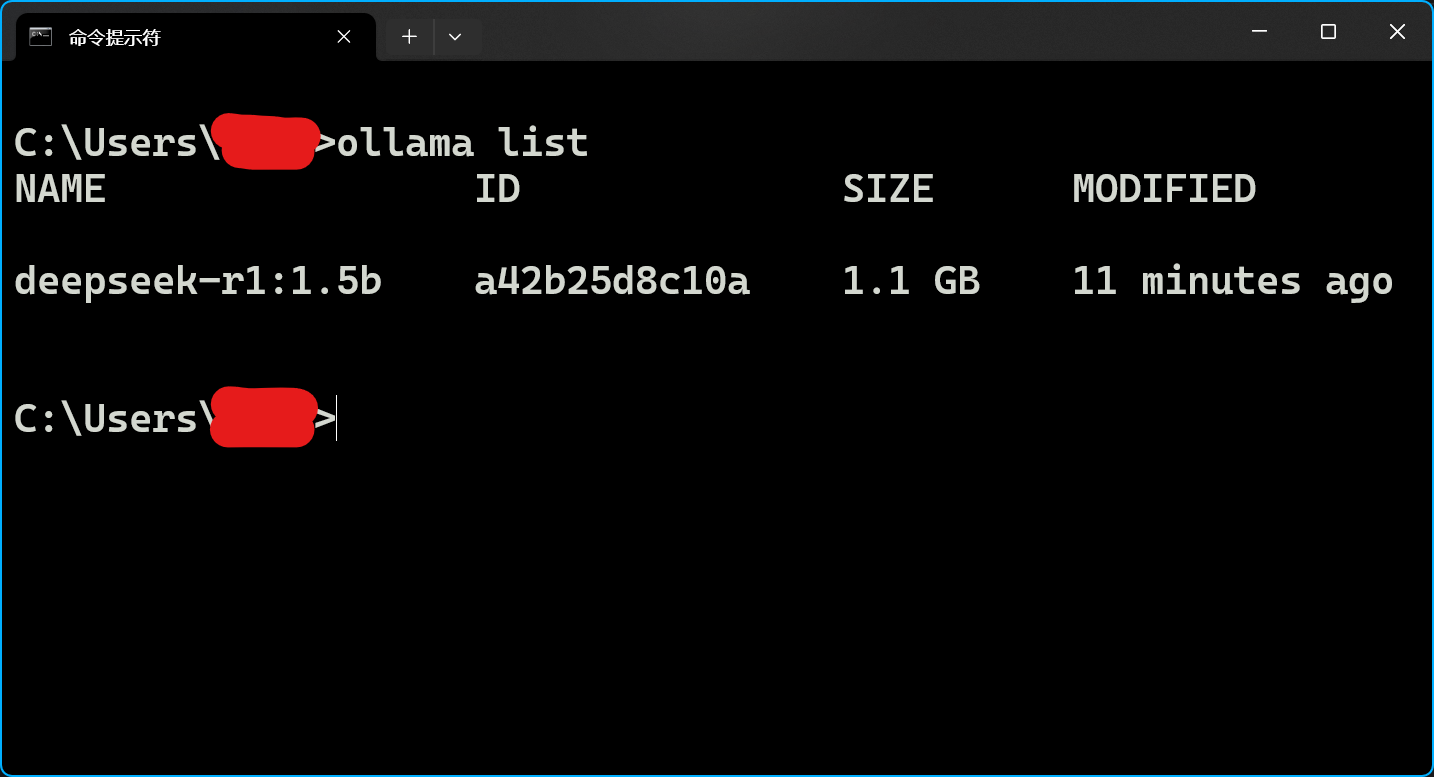
1 | ollama list |
运行模型:
1 | ollama run NAME |
这里的
NAME是使用ollama list后显示的NAME,例如上图中就是deepseek-r1:1.5b,具体取决于你安装了什么。
定制内容
接下来就是本地部署的重头戏了,这里我希望让DeepSeek以一个特定的身份和我说话,比如将其定制为猫娘。
随便找一个文件夹,创建一个没有后缀名的文件,例如cat_girl。
可以使用创建一个
cat_girl.txt的文本文件,并删除.txt后缀来达到同样的结果。
接着用VisualStudioCode打开它,写入代码:
1 | FROM deepseek-r1:1.5b |
注意这里的deepseek-r1:1.5b要替换成你需要自定义的模型,PARAMETER temperature表示创意等级,该参数后面跟着的数字取值范围是0~1小数,如果是0就很严肃,1就像陪聊一样,也可以介于两者之间,如0.5。
接着进入到这个文件的目录下,并使用指令 :
1 | ollama create CatGirl -f ./cat_girl |
这里-f后的文件替换为你刚才创建的文件名,create后跟着的名字就是你的设定名,可以和文件名不同。
完成上述步骤后,再次orrama list
就能看到新创建的模型了,再次使用ollama run CatGirl就能访问新建的猫娘模型CatGirl了,如果你使用了别的名字,换成对应的即可。
WebUI
如果你想使用WebUI来体验Ollama的本地,可以在Chrome浏览器中安装这个插件:Page
Assist - 本地 AI 模型的 Web UI
请现在命令行中用Ollama运行你的模型并将他挂在后台,然后打开浏览器按下快捷键Ctrl+Shift+L就可以打开Web界面。如果你使用了WebUI那么定制起来就方便多了,不需要在本地创建文件,直接在WebUI界面喂给他就好了。
About this Post
This post is written by Sy, licensed under CC BY-NC 4.0.